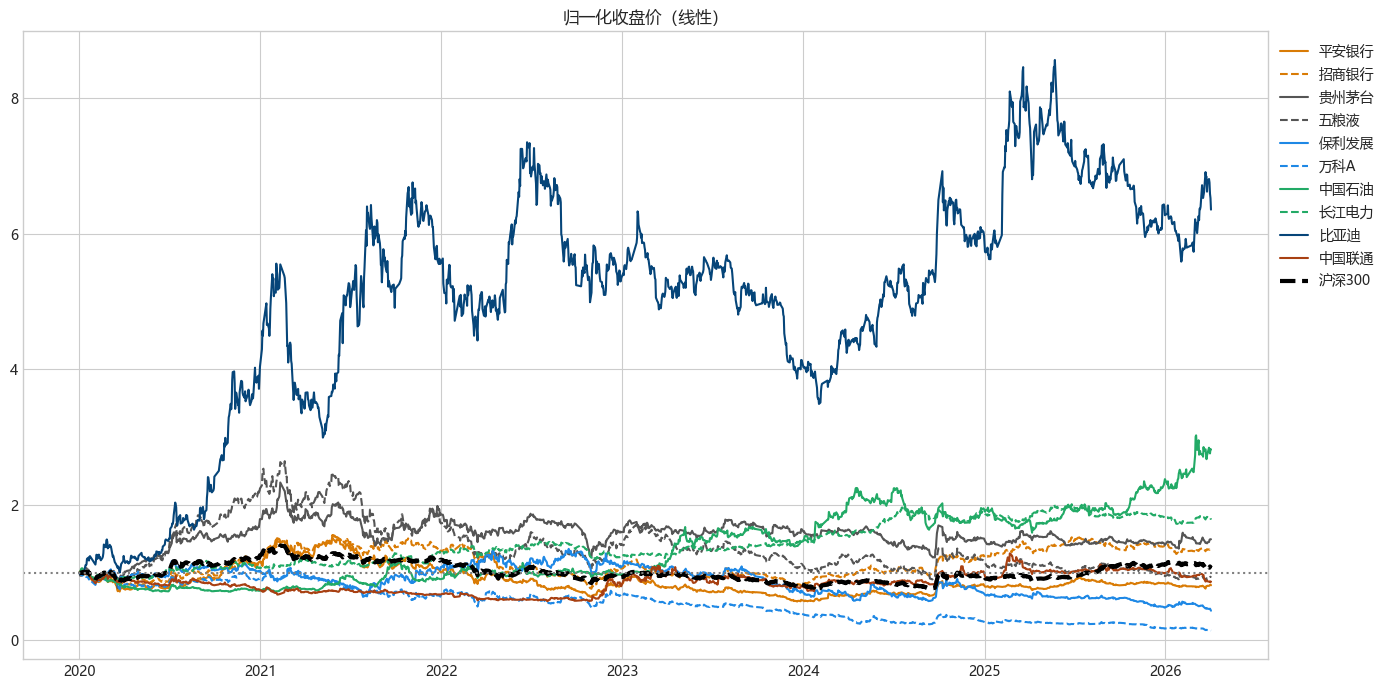
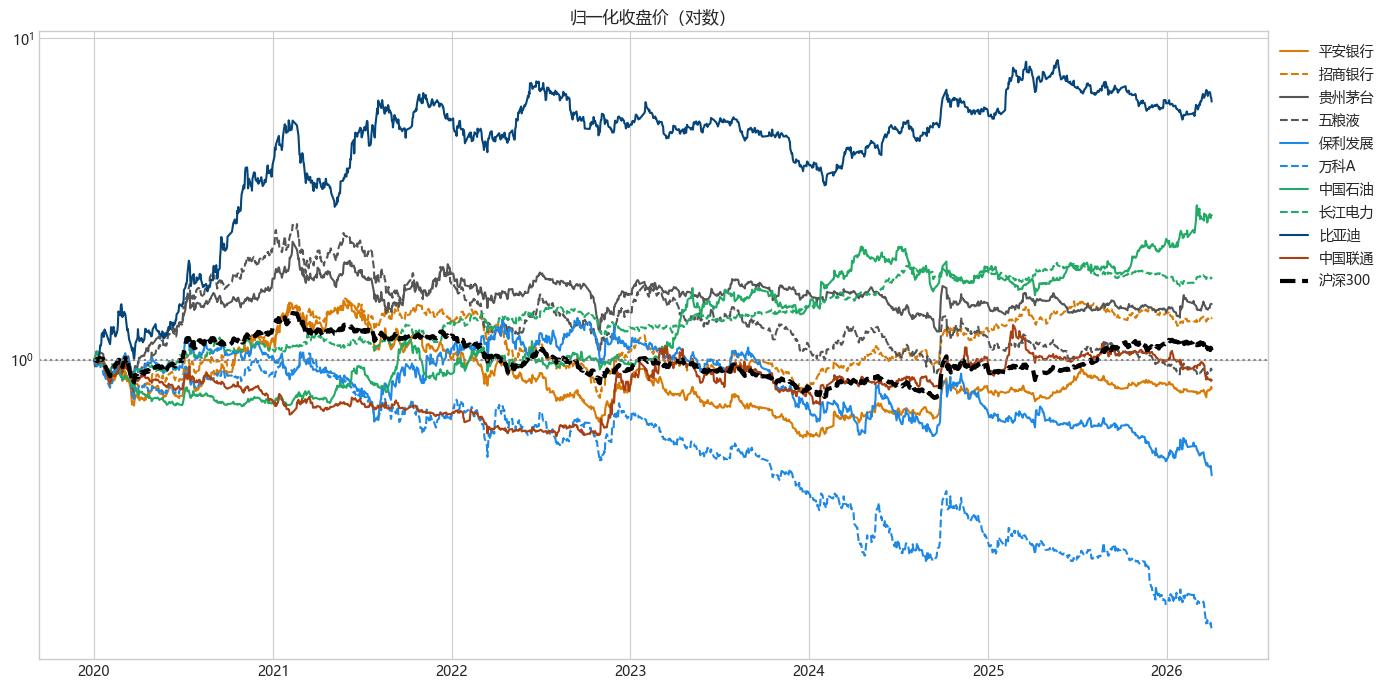
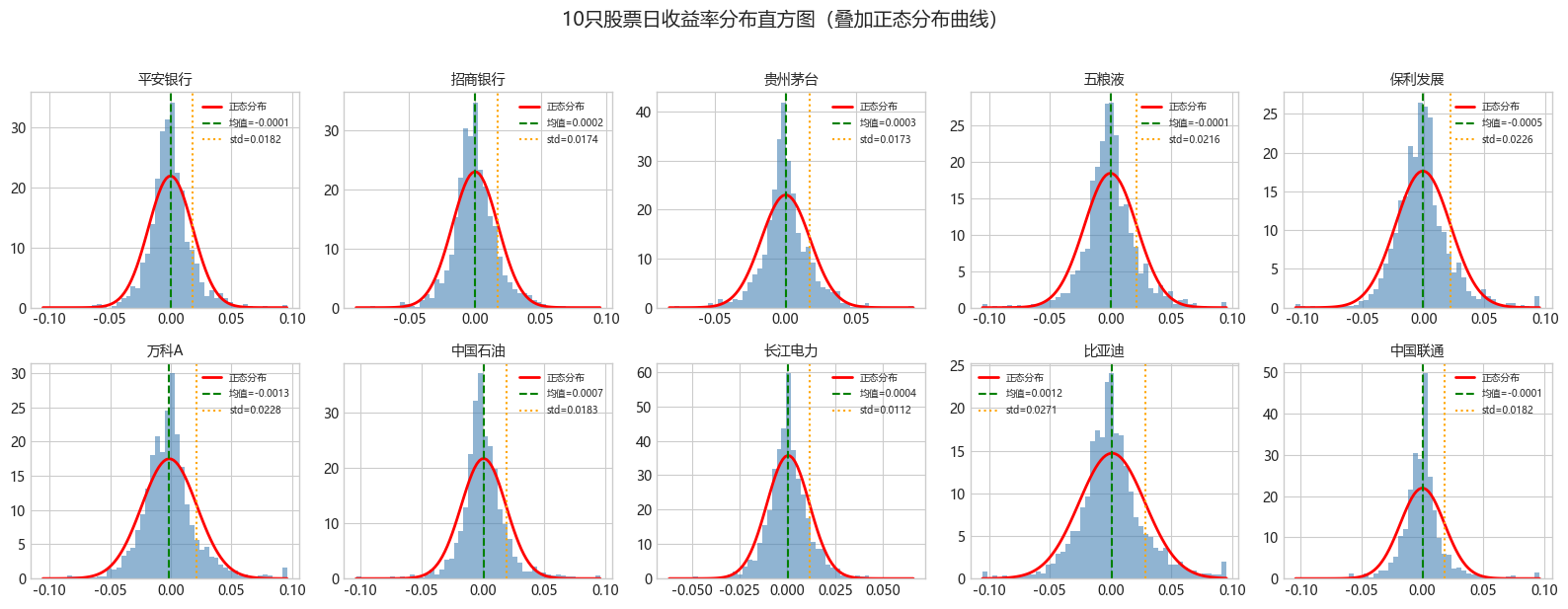
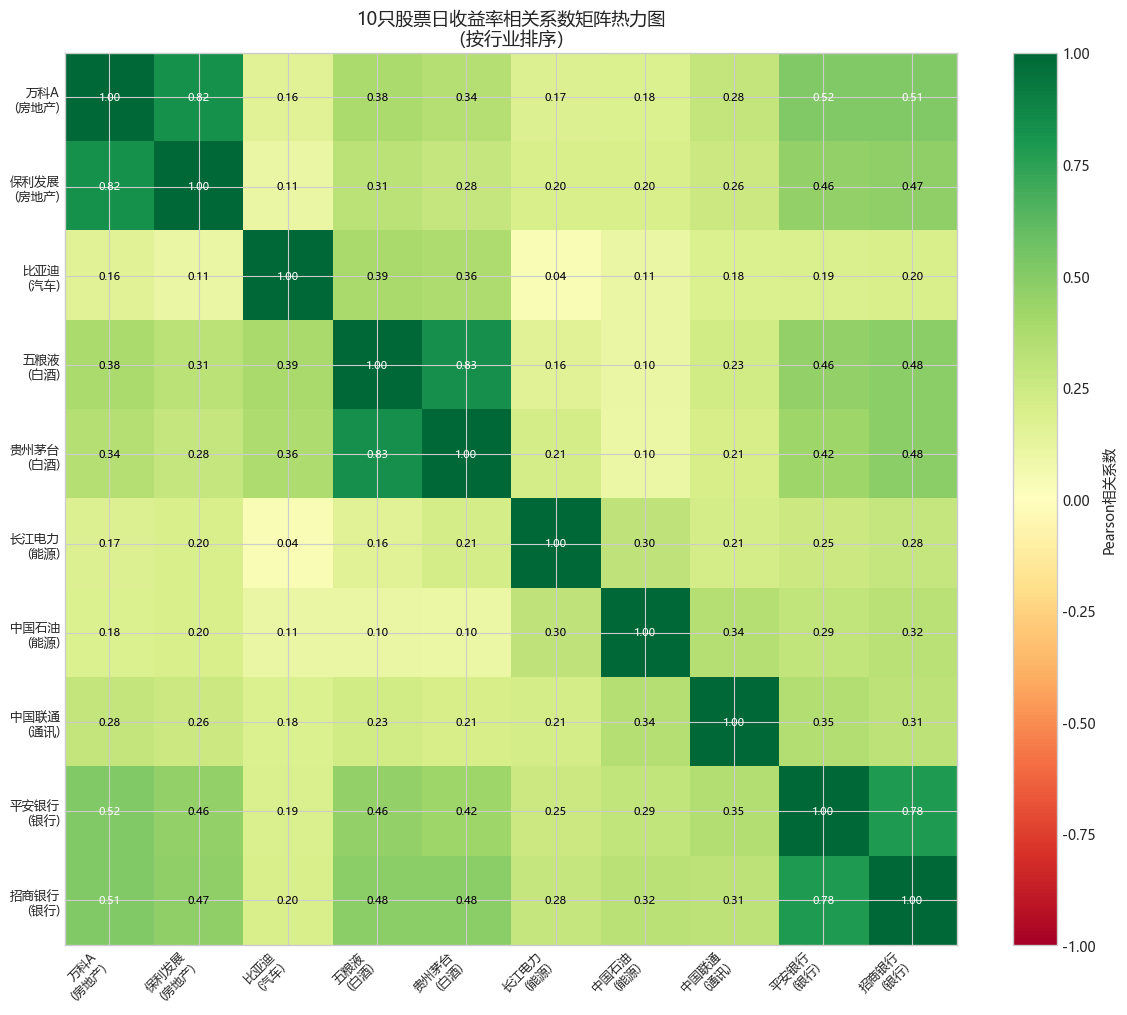
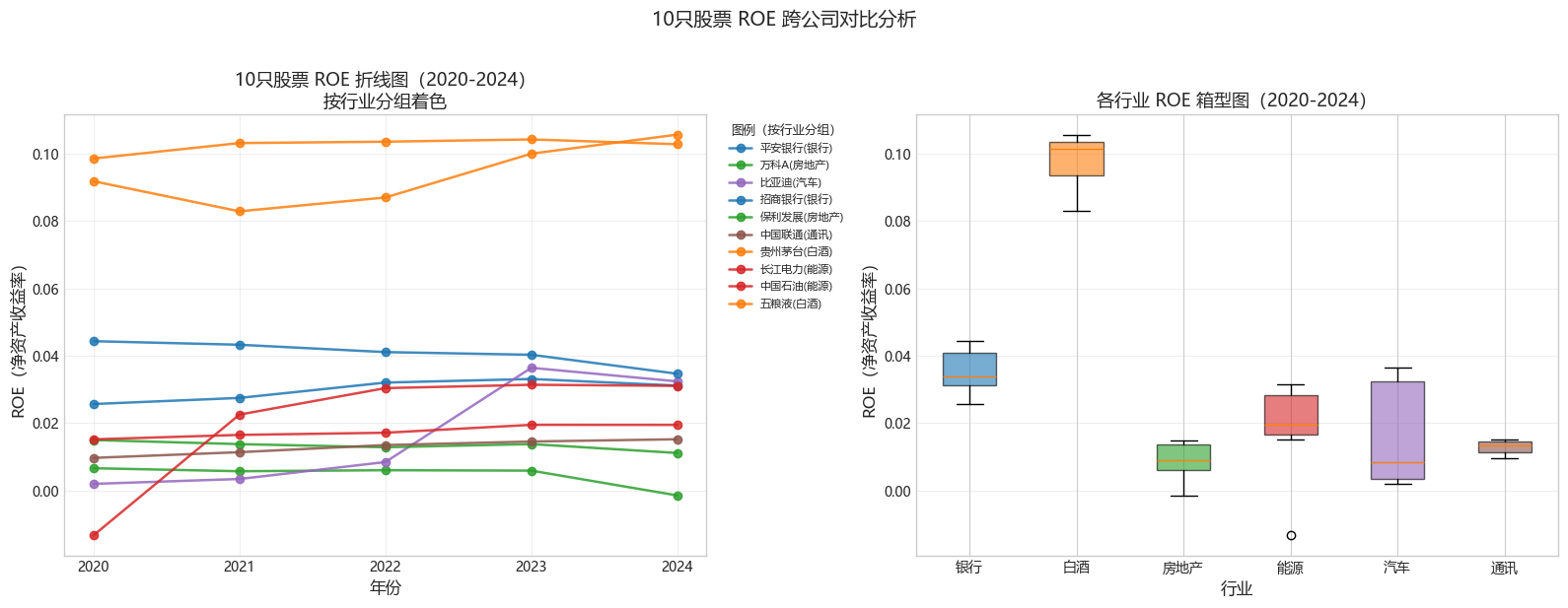
print("=" * 60)
print("图5:ROE 跨公司对比")
print("=" * 60)
fin = pd.read_csv(f"{project_root}/data/finance/finance_ratios.csv")
roe = fin[(fin['indicator'] == 'roeAvg') & (fin['year'] <= 2024)].copy()
roe['year'] = roe['year'].astype(str)
roe['code'] = roe['code'].apply(lambda x: str(int(x)))
stripped_to_name = {str(int(s["code"])): s["name"] for s in stock_list}
stripped_to_industry = {str(int(s["code"])): s["industry"] for s in stock_list}
roe = roe[roe['code'].isin(stripped_to_name.keys())]
roe_pivot = roe.pivot_table(index='code', columns='year', values='value')
roe_pivot = roe_pivot.sort_index()
print(f"ROE数据范围: {roe['year'].min()} - {roe['year'].max()}")
print(f"股票数: {roe['code'].nunique()}")
print("\n各股票 ROE 均值(2020-2024):")
for idx in roe_pivot.index:
name = stripped_to_name.get(idx, idx)
print(f" {name}: {roe_pivot.loc[idx].mean():.4f}")
industry_colors_roe = {
'银行': '#1f77b4', '白酒': '#ff7f0e', '房地产': '#2ca02c',
'能源': '#d62728', '汽车': '#9467bd', '通讯': '#8c564b'
}
years = roe_pivot.columns.tolist()
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax1 = axes[0]
for code_s in roe_pivot.index:
ind = stripped_to_industry.get(code_s, '其他')
name = stripped_to_name.get(code_s, code_s)
ax1.plot(years, roe_pivot.loc[code_s].values,
marker='o', markersize=6,
label=f"{name}({ind})",
color=industry_colors_roe.get(ind, 'gray'), linewidth=1.8, alpha=0.85)
ax1.set_xlabel('年份', fontsize=12)
ax1.set_ylabel('ROE(净资产收益率)', fontsize=12)
ax1.set_title('10只股票 ROE 折线图(2020-2024)\n按行业分组着色', fontsize=13)
ax1.legend(bbox_to_anchor=(1.02, 1), loc='upper left', fontsize=8, title='图例(按行业分组)', title_fontsize=9)
ax1.set_xticks(years)
ax1.grid(True, alpha=0.3)
ax2 = axes[1]
ind_data, ind_labels, ind_colors = [], [], []
for ind in ['银行', '白酒', '房地产', '能源', '汽车', '通讯']:
codes_s = [str(int(s['code'])) for s in stock_list if s['industry'] == ind]
valid = [c for c in codes_s if c in roe_pivot.index]
if not valid:
continue
vals = roe_pivot.loc[valid].values.flatten()
vals = vals[~np.isnan(vals)]
ind_data.append(vals)
ind_labels.append(ind)
ind_colors.append(industry_colors_roe.get(ind, 'gray'))
bp = ax2.boxplot(ind_data, labels=ind_labels, patch_artist=True, notch=False)
for patch, color in zip(bp['boxes'], ind_colors):
patch.set_facecolor(color)
patch.set_alpha(0.6)
ax2.set_xlabel('行业', fontsize=12)
ax2.set_ylabel('ROE(净资产收益率)', fontsize=12)
ax2.set_title('各行业 ROE 箱型图(2020-2024)', fontsize=13)
ax2.grid(True, alpha=0.3, axis='y')
plt.suptitle('10只股票 ROE 跨公司对比分析', fontsize=14, y=1.02)
plt.tight_layout()
plt.savefig(f"{project_root}/output/fig5_roe_comparison.png", dpi=150, bbox_inches='tight')
plt.show()
print("\n图5(ROE对比)已保存至 output/fig5_roe_comparison.png")